관계 데이터 모델의 기본 개념
개념적 구조를 논리적 구조로 표현하는 논리적 데이터 모델
하나의 개체에 대한 데이터를 하나의 릴레이션에 저장

관계 데이터 모델의 기본 용어
ㆍ 릴레이션(relation) : 행과 열로 구성된 테이블
ㆍ ‘릴레이션’ 용어가 포함된 관련 용어

ㆍ릴레이션과, 릴레이션 구성 요소의 공식 용어
행(row) : 투플(tuple)
열(column) : 애트리뷰트 혹은 속성 (attribute)
테이블 : 릴레이션 (relation)
ㆍ도메인 (domain) (DATA TYPE)
하나의 속성이 가질 수 있는 모든 값의 집합
속성 값을 입력 및 수정할 때 적합성의 판단 기준이 됨 - INT에 한글 넣었을 때 작동X, DATA의 정확성에 초점.
일반적으로 속성의 톡성을 고려한 데이터 타입으로 정의
예: 문자형, 숫자형
ㆍ널(null)
속성 값을 아직 모르거나 해당되는 값이 없음을 표현
숫자 0도 아니고, 공백도 아닌 값
ㆍ차수(degree) = TABLE의 열 수
한 릴레이션에 들어있는 속성의 개수
유효한 릴레이션의 최소 차수는 1
자주 바뀌지 않음
ㆍ카다널리티(cardinality) = TABLE의 행 수
릴레이션의 투플 수
유효한 릴레이션의 최소 카다널리티 수는 0 (DATA ZERO)
시간이 지남에 따라 계속해서 변함

< 고객 릴레이션의 차수는 6, 카디널리티는 4 >
릴레이션의 구성
릴레이션은 스키마와 인스턴스로 이루어진다.
ㆍ릴레이션 스키마 (schema)
릴레이션의 논리적 구조
릴레이션 이름과 속성이름으로 정의 예) 고객(고객아이디, 고객이름, 나이, 등급, 직업, 적립금)
릴레이션의 틀
자주 바뀌지 않음
ㆍ릴레이션 인스턴스 (instance)
릴레이션에 실제 저장되는 데이터의 집합
어느 한 시점에서 릴레이션에 포함되어 있는 투플들의 집합
시간이 지남에 따라 계속해서 변함
예)

관계 데이터 모델의 장점
ㆍ바탕이 되는 데이터 구조로서 간단한 테이블(릴레이션)
중복된 복잡한 구조가 없음 ( TREE, GRAPH에 비해 그대로 표현되거나, 복잡한 구조의 경우 표현할 수 없다. )
다른 데이터 모델에 비해 이해가 쉬움
ㆍ다른 데이터 모델에 비해 이론적인 토대가 잘 만들어져 있음
ㆍ다른 데이터 모델에 비해 실제 적용한 사례가 매우 풍부
안정적
좋은 성능
릴레이션의 특성
릴레이션의 특성을 갖춘 행과 열을 릴레이션이라고 한다.
ㆍ투플의 유일성 -> 중복 최소화, 동일한 것은 버린다.
1개의 릴레이션에는 동일한 투플이 존재할 수 없음
릴레이션은 서로 다른 투플들의 “집합”
ex) 일란성쌍둥이 이지만 주민번호, 지문은 다르다. 이처럼 특정한 부분이 다르다면, 다르다고 말할 수 있다.
키(Key)가 존재함
릴레이션의 키 : 각 투플을 고유하게 식별할 수 있는 하나 이상의 속성들의 모임
ㆍ속성의 원자성
한 투플의 각 속성은 단일값(원자값,atomic value)을 가짐
속성값은 분해 불가능
예: “직업” 속성은 허용되지 않음( 이유 : 단일값 아님 ) - 다중 값 허용X
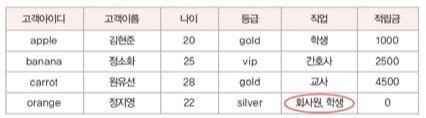
쪼개어 지기 때문에 속성의 원자성에 위배된다.
ㆍ투플의 무순서
투플들의 순서는 무의미

두 개의 TABLE는 같다.
ㆍ속성의 무순서
속성들의 순서는 무의미

ㆍ한 속성의 값은 모두 같은 도메인 값을 가진다.
한 속성에 속한 데이터값은 모두 그 속성에서 정의한 도메인 값만 가질 수 있음
예) ‘고객’ 릴레이션의 ‘나이’속성 : ‘고객’ 릴레이션 내의 어떤 투플에서도 숫자형이 아닌 값은 허용 되지않음
ㆍ속성은 서로 다른 이름을 가진다
한 릴레이션에서, 속성은 서로 다른 이름을 가져야만 함
주의) 서로 다른 릴레이션간에는 같은 이름을 가진 속성이 있어도됨
예) 제품(제품번호,이름,가격) 고객(고객번호,이름) 이 예의 이름은 구별이 가능하다 때문에 OK!
예 : 아래 ‘도서’ 릴레이션은 릴레이션이라고 볼 수 있는가?
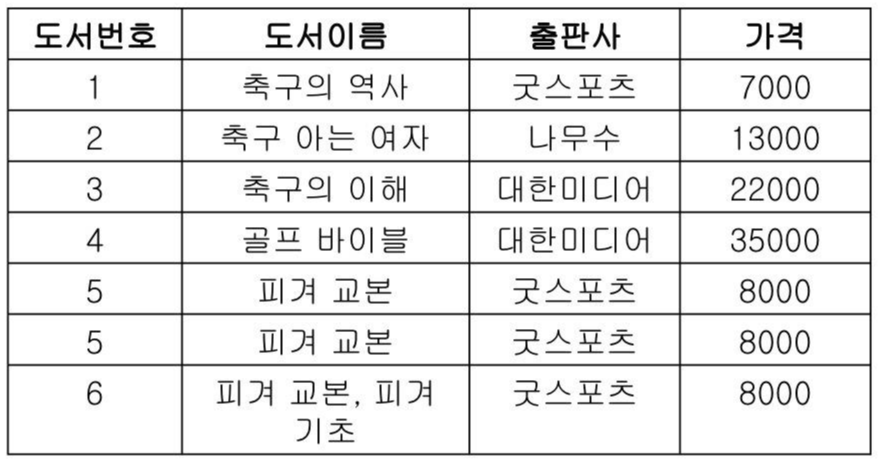
튜플의 유일성(5,5), 원자성(피겨교본, 피겨기초)이 위배 되었다.
릴레이션의 키(Key)
ㆍ릴레이션에서 투플을 유일하게 식별할 수 있는 속성 혹은 속성들의 집합
ㆍ릴레이션은 중복된 투플을 허용하지 않기 때문에 각각의 투플에 포함된 속성들 중 어느 하나 (혹은 하나 이상)는 값이 달라야 한다.
ㆍ즉, 키가 되는 속성 (혹은 속성의 집합)은 반드시 값이 달라서 투플들을 서로 구별할 수 있어야 한다.
ㆍ키의 종류 : 슈퍼키, 후보키, 기본키
키 (Key) : 슈퍼키 (Super Key) - 다 가지고 있다.
ㆍ투플을 유일하게 식별할 수 있는 하나의 속성 혹은 속성들의 집합 - 튜플을 구분할 수 있기만 하면 된다.
ㆍ투플들을 고유하게 식별하는데 꼭 필요하지 않은 속성들을 포함할 수 있음
ㆍ1개 이상 존재
ㆍ예 : 고객(고객번호, 이름, 주민번호, 주소, 핸드폰)
슈퍼키 (여러 개 일 수 있다.(조합))
(고객번호)
(주민번호, 이름, 주소)
(고객번호, 이름, 주민번호, 주소, 핸드폰)
...
키 (Key) : 후보키( candidate Key) - 의미 없는 것은 버린다.
ㆍ투플을 유일하게 식별할 수 있는 속성들의 최소 집합
ㆍ모든 릴레이션에는 최소한 1개 이상의 후보키가 있음

ㆍ예: 고객( 고객번호, 이름, 주민번호, 주소, 핸드폰)
(고객번호) 슈퍼키O 후보키O
(주민번호, 이름, 주소) 슈퍼키O 후보키X
ㆍ예: 주문(고객번호,도서번호,판매가격,주문일자)
후보키는? (고객번호, 도서번호)
ㆍ후보키도 2개 이상의 속성으로 이루어질 수 있다.
키 (Key) : 기본키 (primary Key)
ㆍ여러 후보키 중 하나를 선정하여 대표로 삼는 키
후보키가 1개인 경우는, 후보키가 기본키가 된다.
ㆍ릴레이션당 기본키는 1개만 존재
ㆍ기본키 선정 시 고려사항
후보키가 여러 개인 경우, 릴레이션의 특성을 가장 잘 반영하는 1개를 선택
속성값으로 널(Null) 값은 허용하지 않는다.
속성값의 변동이 일어나지 않을수록 좋다.
최대한 적은 수의 속성을 가질수록 좋다.
ㆍ예: 고객(고객번호,이름,주민번호,주소,핸드폰)
후보키는? 주민번호, 고객번호, 핸드폰
기본키는? 고객번호
ㆍ키를 선정하는 경우의 절차
1단계 : 수퍼 키 찾기
2단계 : 수퍼 키를 최소화하여, 이로부터 후보 키 찾기
3단계 : 여러 개의 후보 키 중, 반드시 1개의 기본 키 선정
ㆍ예 : 고객(고객번호, 이름, 주민번호, 주소, 핸드폰)
수퍼 키 : (고객번호),(고객번호,이름),(주민번호),(주민번호,주소),(핸드폰),(고객번호,휴대폰),,
후보 키 : (고객번호), (주민번호), (핸드폰)
기본 키 : (고객번호)
ㆍ릴레이션 스키마를 표현할 때 밑줄을 그어 표시한다.
ㆍ릴레이션 이름(속성1,속성2, ... 속성N)
ㆍ예: 고객(고객번호, 이름, 주민번호, 주소, 핸드폰), 도서(도서번호, 도서이름, 출판사, 가격)
핸드폰 : 속성값의 변화가 있을 수 있으므로 제외
고객번호와 주민번호 중 고객 릴레이션의 특성을 더 잘 반영할 수 있는 고객번호를 기본키로 설정.
ㆍ예: 학생 릴레이션

ㆍ이름이 후보 키가 될 수 있는가? NO
(위의 DATA만 보는 것이 아니라, 현실세계를 이해해야한다.)
ㆍ이메일이 후보 키가 될 수 있는가? YES
키 선정은 릴레이션 스키마를 통해 결정할 것 (인스턴스만을 보고 결정하지 말 것)
Question
학생(학번, 주민번호, 이름, 학년, 학과)
과목(과목번호, 과목이름, 이름, 담당교수이름)
등록(학번, 과목번호, 성적)
Q1) 슈퍼키 두 개씩
학생 - 학번, 주민번호 과목 - 과목번호, 이름
등록 - 학번, 과목번호
Q2) 후보키, 기본키
기본키 학생 - 학번, 과목 - 과목번호, 등록 - 학번
후보키 학생 - 학번,주민번호 과목 - 과목번호, 등록 - 학번,과목번호
'개발 > Database' 카테고리의 다른 글
| 데이터베이스 관계 대수 연산자 - 집합 연산자 (0) | 2020.07.14 |
|---|---|
| 데이터베이스 관계 데이터 연산 - 관계 대수 (0) | 2020.07.14 |
| 데이터베이스 모델링 - 개념 (0) | 2019.12.21 |
| 데이터베이스 언어 & 사용자 & 구성 (0) | 2019.12.21 |
| 데이터베이스 시스템의 구조 (0) | 2019.12.21 |



